DreamOps to Riquell Ops: A Hackathon Win to Product
When we stepped into Warpspeed 2025 in Bengaluru, we were surrounded by some of the brightest minds in the AI space. Organized by Devfolio and Lightspeed India, the hackathon was buzzing with energy and big ambitions. We knew the odds were tough, but we also knew that every big leap starts with a small idea — and this was our chance to take that leap together.
What followed was a whirlwind of brainstorming, coding, and sleepless hours with our team — Himanshu, Akash Singh, and Inchara J. By the end of those 24 hours, we had built something that not only won the hackathon but also set the foundation for our internships, where we’re now turning that very idea into a real product. Later, Shubhang Sinha joined us as part of the journey, helping shape and refine the project as we continued building it beyond the hackathon stage.

Where the Idea Sparked
Every good project starts with a real problem, and for us, it came straight from our teammate Akash Singh. As a DevOps engineer, he had been dealing with the tough responsibility of being an on-call agent at his company — the person who gets paged when something breaks in production. Anyone who’s been on-call knows the stress: late-night alerts, urgent debugging, and the pressure to restore systems quickly.
That pain point made us think — what if we could build an AI on-call assistant that could jump in the moment an issue occurs? That’s how DreamOps was born. It’s an AI-powered on-call agent designed to diagnose production errors, prepare a plan of action, and in some cases even begin execution before the human on-call engineer gets involved. Thanks to what we call “YOLO mode”, DreamOps doesn’t just wait around; it proactively takes steps to reduce downtime and give engineers a head start.
How It Really Works
Every on-call engineer knows the pain — your phone buzzes at 3 AM, and suddenly you’re the last line of defense between production chaos and a peaceful night’s sleep. DreamOps was built to flip that script. Here’s how it actually works under the hood:
- Alert Lands
- The moment PagerDuty or any on-call system raises an alert, DreamOps doesn’t wait for a human.
- It steps in immediately, pulling the full incident payload and preparing for triage.
- Context Loading
- Instead of a sleepy engineer digging through dashboards, DreamOps automatically gathers:
- Logs from containers and pods
- Metrics from monitoring tools like Grafana
- Kubernetes deployment states and configs
- Relevant past incident history
- Within seconds, it has more context than most humans could gather in 10–15 minutes.
- Instead of a sleepy engineer digging through dashboards, DreamOps automatically gathers:
- Root Cause Reasoning
- Using advanced AI reasoning, it connects the dots across logs, metrics, and configs.
- Example: If a pod is restarting with
CrashLoopBackOff, DreamOps checks memory patterns, recent config pushes, and known issue signatures before making a call.
- Drafting a Plan of Action
- DreamOps doesn’t just shout “something’s wrong.”
- It drafts a full remediation plan, ranking possible fixes with confidence scores.
- Every action is tagged as Low, Medium, or High Risk so engineers know exactly what’s at stake.
- Smart Execution
- If confidence ≥80% and risk is low, DreamOps executes the fix immediately (restart a pod, clear a stuck job, roll back a bad config).
- If the risk is higher, it pings the on-call engineer with a ready-to-run command set. By the time they open their laptop, the plan is waiting.
- YOLO Mode (Yes, we called it that!)
- For routine, well-understood problems, YOLO Mode takes full control.
- Things like OOMKilled pods, failed deployments, or config rollbacks get fixed on their own—no humans woken up.
- But don’t worry, YOLO isn’t reckless. Every move still goes through risk assessment before execution.
- Continuous Learning
- Every incident is a lesson. DreamOps logs what worked, what didn’t, and refines its playbooks.
- Over time, it builds an internal “battle-tested knowledge base” — meaning the more it runs, the sharper it gets.
The Outcome?
Incidents that normally drag on for 30–60 minutes now close in 2–5 minutes. Engineers don’t just get fewer wake-up calls—they wake up to find the problem already solved, with a detailed report of what happened.
The Actual Flow 🔄
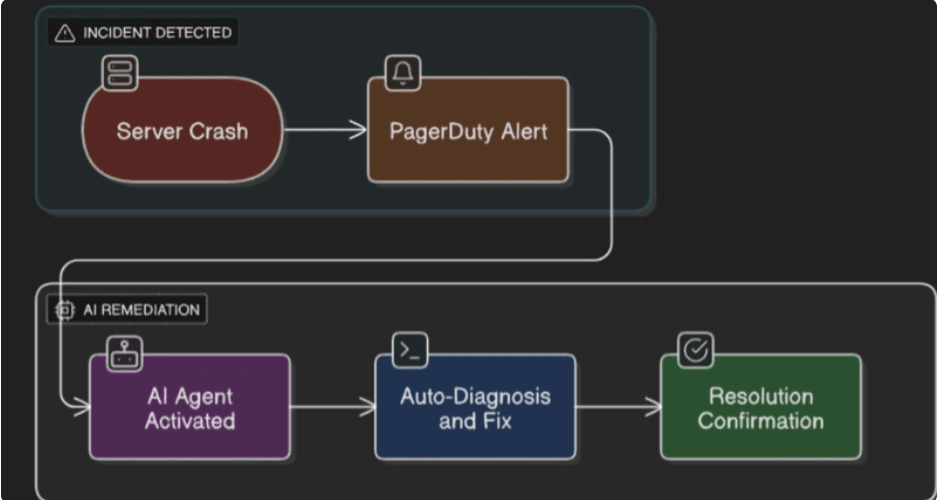
To understand DreamOps better, let’s walk through the flow of how it handles incidents. The diagram above captures the high-level journey:
- Incident Detected
- It all starts with something breaking in production — for example, a server crash.
- Traditionally, this would immediately ping the on-call engineer, but with DreamOps in the loop, things look different.
- PagerDuty Alert Raised
- PagerDuty (or any alerting tool) still does its job — it raises the alarm.
- But instead of ringing only a human’s phone, the alert is also forwarded to DreamOps’ AI agent.
- AI Agent Activated
- The AI instantly wakes up and gets to work.
- It pulls in relevant context: system logs, Kubernetes states, monitoring dashboards, and past incident patterns.
- Auto-Diagnosis and Fix
- Within seconds, the agent diagnoses the issue and drafts a fix.
- If confidence is high and the action is low-risk (like restarting a pod or clearing a cache), DreamOps executes automatically.
- If the risk is higher, it prepares a ready-to-run remediation plan for the on-call engineer.
- Resolution Confirmation
- Once the fix is applied, DreamOps verifies that the system is back online.
- This confirmation is logged, and a neat incident report is generated for the engineering team.
Under the Hood: What Makes DreamOps Tick
DreamOps might have started at a hackathon, but it’s been engineered with real-world reliability in mind. Here’s a look at the tech backbone that powers it:
AI-First Architecture
- Claude AI at the Core – Handles reasoning and root cause analysis, like having a senior DevOps engineer who never sleeps.
- Model Context Protocol (MCP) – Lets DreamOps plug into 10+ popular tools without messy integrations.
- Smart Confidence Scoring – No blind guesses. The AI only executes fixes automatically when it’s ≥80% sure.
- Safety via Risk Levels – Every action is tagged low, medium, or high risk — so you know exactly what’s happening.
A Stack Ready for Production
- Backend – Powered by Python FastAPI, built for speed and async workloads.
- Frontend – Sleek Next.js dashboards to monitor incidents in real time.
- Infrastructure – Runs on AWS ECS/EKS, designed to scale with heavy production loads.
- Integrations That Matter – Works seamlessly with Kubernetes, PagerDuty, Grafana, GitHub, Slack, Notion.
I was responsible for handling the full-stack development, from designing the Next.js frontend to wiring up the backend APIs. On top of that, I took charge of the MCP (Model Context Protocol) integration — even though it was completely new to me. Figuring out how to make multiple external tools talk seamlessly with our AI agent was a challenge, but one that pushed me to grow fast during the hackathon.
The Winning Moment🏆
After 24 hours of intense brainstorming, debugging, and coding, we finally had something we were truly proud of. But nothing could prepare us for the moment when DreamOps was announced as one of the winners of Warpspeed 2025.
The room filled with applause, and in that instant, all the sleepless hours and caffeine-fueled struggles felt worth it. Standing together as a team — Himanshu, Akash Singh, Inchara J, and me — we realized this wasn’t just another hackathon project. DreamOps had struck a chord with both the judges and the community because it addressed a challenge every on-call engineer could relate to.
Winning the $3,000 prize wasn’t just about money or recognition. It was validation — a clear sign that our idea carried real-world potential, with the power to grow beyond a weekend hack and evolve into something meaningful.
From Hackathon Project to Real Product
Winning Warpspeed 2025 gave us more than just validation — it gave us the conviction to take DreamOps beyond the hackathon stage. We decided that this idea deserved to live as a real product, one that could genuinely change how on-call engineering is done.
That’s when DreamOps became Riquell Ops. Along with the new name came a stronger technical foundation — we shifted our backend from Python FastAPI to Go, ensuring greater performance, scalability, and production readiness.
Since then, we’ve been focused on expanding its capabilities: building new integrations, refining the AI agent’s intelligence, and making sure it fits seamlessly into the modern DevOps ecosystem. What started as a weekend project is steadily evolving into a platform designed to support real teams, in real production environments.

How It Opened Doors to Our Internship
Turning our hackathon win into a story didn’t stop at the event. We shared our journey and the vision behind DreamOps (now Riquell Ops) on LinkedIn and X (Twitter), hoping to inspire others and spark conversations around the future of on-call engineering.
What happened next was beyond our expectations — our idea caught the attention of an AVP at ICICI, who saw real potential in what we were building. Impressed by the problem we were solving and the progress we had already made, he reached out and offered us an internship opportunity to continue developing our own product inside a real-world setting.
This internship became the bridge between a hackathon prototype and a production-grade solution — giving us not just resources, but also mentorship and validation from an industry leader.
The Team Behind the Magic
- Akash (Sky) Singh – Lead Developer & DevOps
- Inchara J – AI/ML Engineer
- Himanshu – Frontend Developer & MCP Integration
- Harsh Kumar Gupta – Backend & MCP Integration
- Shubhang Sinha – AI Engineer (post-hackathon)